1. 学習用のデータセットを作る
まずは学習用の画像を収集し、データセットを作成します。
データセットについて
物体認識を行うには、認識させたい物体の画像を大量に収集し、それを学習させる工程が必要です。
認識させる物体の種類の数だけ画像を収集する必要がありますし、同じ物体の画像が多ければ多いほど(基本的には)認識精度が向上します。
ただし、画像が多いほど、アノテーション(次章)が大変になりますし、学習に時間がかかるようになります。最低でも1種類につき100枚程度はあると良いでしょう。
今回は、データセットを作成する方法として、画像を撮影する方法とGoogle画像検索から自動収集する方法を紹介します。
もちろん、手元に画像が揃っていれば、それを使っても構わないです。
1-1. akari_dataset_creatorのClone
akari_dataset_creatorをgitからcloneします。
webコンソール上からはcloneせず、Ubuntu上でのcloneを実施してください!
git clone https://github.com/AkariGroup/akari_dataset_creator.git
1-2. (初回のみ) venvのセットアップ
仮想実行環境をセットアップします。
cd akari_dataset_creator
python -m venv venv
source venv/bin/activate
pip install -r requirements.txt
1-3. 画像を収集する
画像を撮影する
venvを有効化していなければ下記を実行します。
source venv/bin/activate
AKARIで画像を撮影しながらデータセットを作っていきます。
0. 事前準備をする でcloneしたakari_dataset_creatorへ移動し、画像撮影用アプリケーションを起動します。
この際、-nオプションで認識したい物体名を指定します。撮影した画像はここで付けた名前と共に連番が振られます。
例) ペンの画像を撮影するため、"pen"という名前をつける場合
python3 imageset_creator.py -n pen
実行すると現在のカメラ映像を写すウィンドウが起動します。
このウインドウ上でキーボードの'c'を押すと、その度に画像を撮影していきます。
'pen'の例の場合は、'pen'というディレクトリが作られ、その中に'pen_001.jpg','pen_002.jpg'...という画像が保存されていきます。
映像ウインドウ上でキーボードの'q'を押すと終了します。
また、'-a'オプションと共にfpsの数値を指定すると、1秒間に指定した数値の枚数を自動で撮影するモードを使用することができます。
例) "dog"という名前で1秒あたり2枚の画像を自動撮影する場合
python3 imageset_creator.py -n pen -a 2
この場合も映像ウインドウ上でキーボードの'q'を押すと終了します。
注釈
より良いデータセットを作るためには、物体の向きや種類を変えながら、なるべく色々なパターンの画像を撮りましょう。
ペンの例で言うと、ある1種類のペンを認識したいならそのペンだけを、色々なペンを同じペンとして認識させたいのであれば、なるべく多くの種類のペンの画像を撮ることが大事です。
Google画像検索から画像を自動収集する
汎用的なものの画像であれば、Google画像検索から自動収集する方法が使えます。
下記の手順でを行います。
google image downloadのレポジトリをgit cloneします。
git clone https://github.com/janvdp/google-images-download.git
ライブラリのインストールを行います。
cd google-images-download
uv init
uv add install selenium==4.0.0
uv run setup.py install --user
google chromeをインストールします。
sudo sh -c 'echo "deb http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google.list'
sudo wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | sudo apt-key add -
sudo apt update
sudo apt install google-chrome-stable
先程インストールしたchromeのバージョンを確認します。
apt list | grep google-chrome-stable
choromeのバージョンと同じバージョンのchromedriverを下記リンク先からダウンロードします。
versionの同じchromedriverのlinux64版のリンクをコピーし、下記のコマンドでダウンロードします。
wget "コピーしたchromedriverのリンク"
ダウンロードしたzipファイルを展開し、中に含まれる chromedriver ファイルを任意の場所に移動します。
cdコマンドで画像収集したいディレクトリに移動し、googleimagesdownloadを実行します。
-l オプションで枚数、 -k オプションで検索ワード、 -f オプションで拡張子、 -cd オプションで4.でダウンロードしたchromedriverまでのパスを指定します。
例) 120枚の犬の画像をjpg形式で収集する場合。(chromedriverをhome直下に保存している場合)
googleimagesdownload -l 120 -k 'ペン' -f jpg --chromedriver ~/chromedriver
画像収集が実行され、実行したディレクトリに downloads ディレクトリが作られ、その中に画像が収集されます。
画像検索結果なので、全然違うものなど認識の学習に適さない画像も混ざっています。必ず中身をチェックして、不要なものは削除しましょう。
1-4. 画像の名前、ファイル形式などを整理する。
手元にある画像やGoogle検索などで集めた画像の場合、名前や拡張子がバラバラで扱いづらいです。
特に今回のプロセスでは、画像を.jpgに統一する必要があります。
ここでは、自動整理ソフトを使って、ディレクトリ内の画像を一括で連番、jpg変換を行います。
同じ種類のタグを付けたい画像を、一つのディレクトリ内にまとめます。
akari_object_detection/1_image_collectionへ移動し、image_converter.pyを実行します。
-d オプションで変換したい画像が保存されているディレクトリのパス、 -n オプションでタグ名を指定します。
例) ~/image/pen ディレクトリに保存されているペンの画像に'pen'というタグ名を付けたい場合
python3 image_converter.py -d ~/image/pen -n pen
画像形式が自動で.jpgに変換され、"タグ名_000.jpg","タグ名_001.jpg"...と連番にリネームされます。
画像形式変換可能な形式は、 .png と .gif です。 .jpeg や .JPG も.jpgに変換されます。
1-5. 画像ディレクトリを整理する。
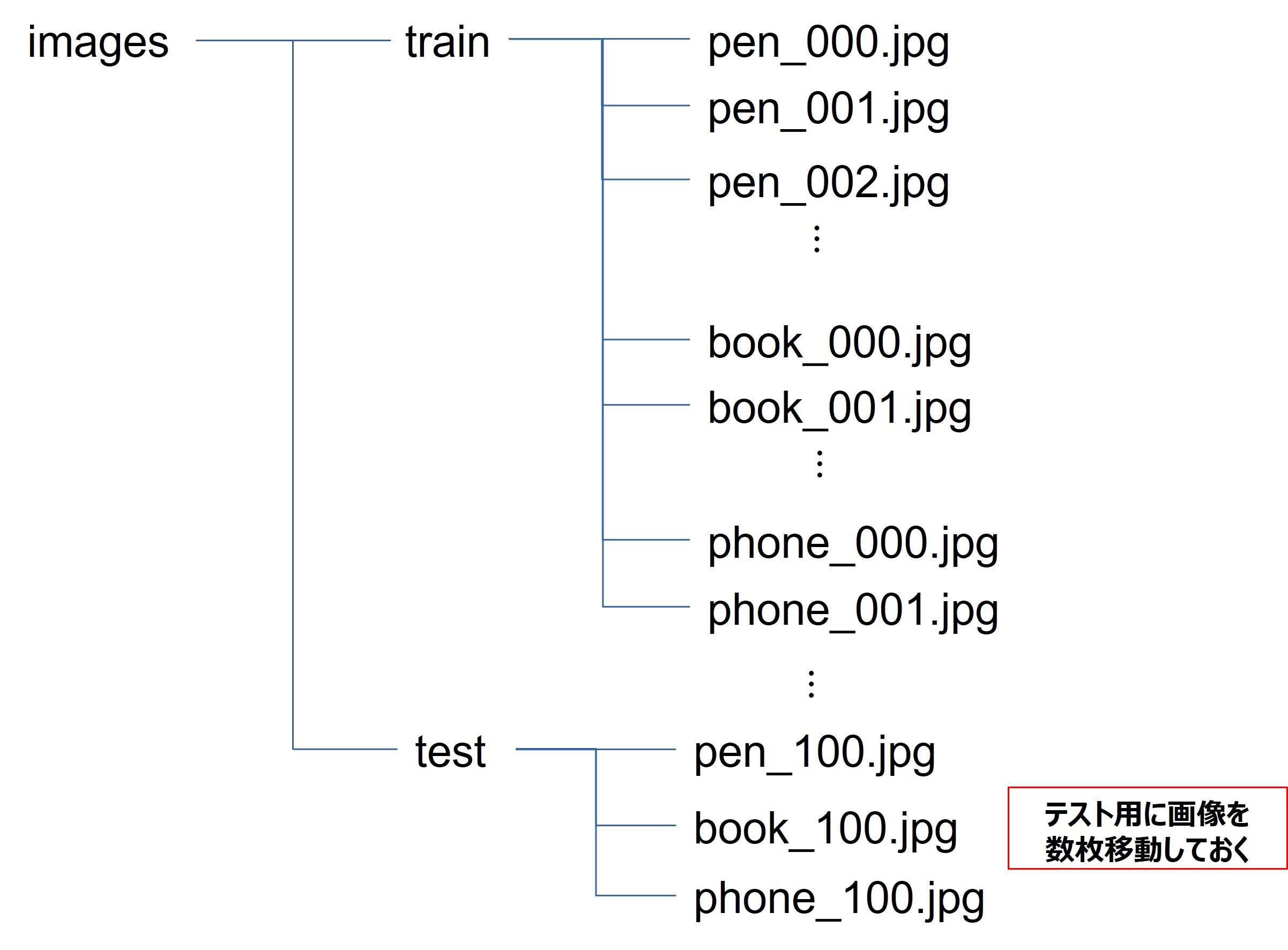
学習させるための各画像のディレクトリは、下図のように整理しておきます。
imagesの下にtrain,testというディレクトリを作成し、trainの下に各画像をラベルごとにディレクトリ分けし、testの下にはtrainからラベルごとに数枚ずつ、画像を移動しておきます。
移動する画像はどれでもいいですが、通し番号の最後のものを移動するのが分かりやすいと思います。
testの下はラベルごとにディレクトリ分けする必要はありません。
例) pen,book,phoneの3種類を学習させたい場合
画像が揃ったら、次は学習用のラベル付けをする、 アノテーション という工程に進みます。
2. 画像のアノテーションをする へ進む
0. 事前準備をする へ戻る